Scraping Wikipedia for Game of Thrones Data
The fantasy epic Game of Thrones offers some interesting data that sociologists can use to draw conclusions about audience growth and interest. Despite the series’s interest, few datasets have been created to capture audience behaviour and uptake. However, this data does exist in various fan websites including Wikipedia.
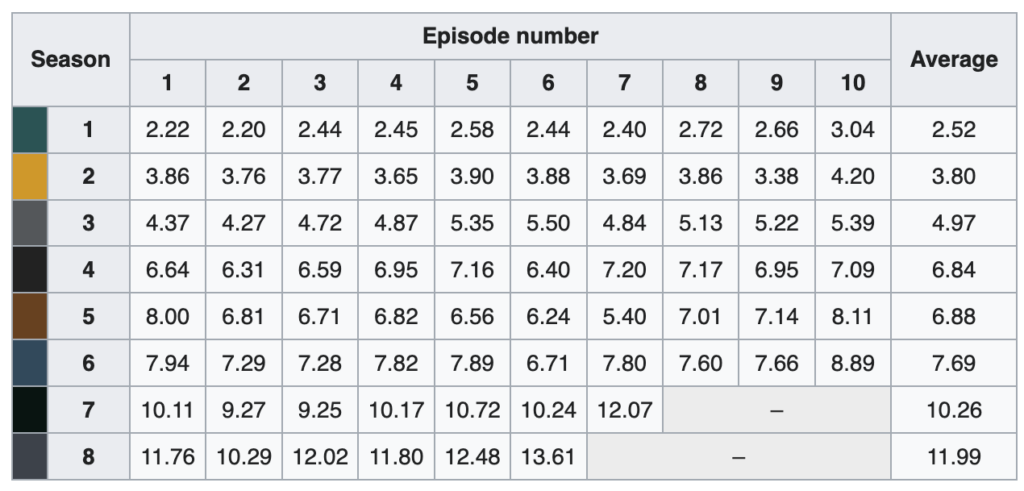
This short web scraping script exploits the ‘requests’ and ‘Beautiful Soup libraries to extract the episode viewing number data from Wikipedia. Here is a screenshot of the table for the viewing figures by epsiode, which can find here.
Please note that the code here is written as a learning exercise and is not the most efficient way to undertake this task As your Python skills improve you’ll find better, more ‘Pythonic’ ways to write this code.
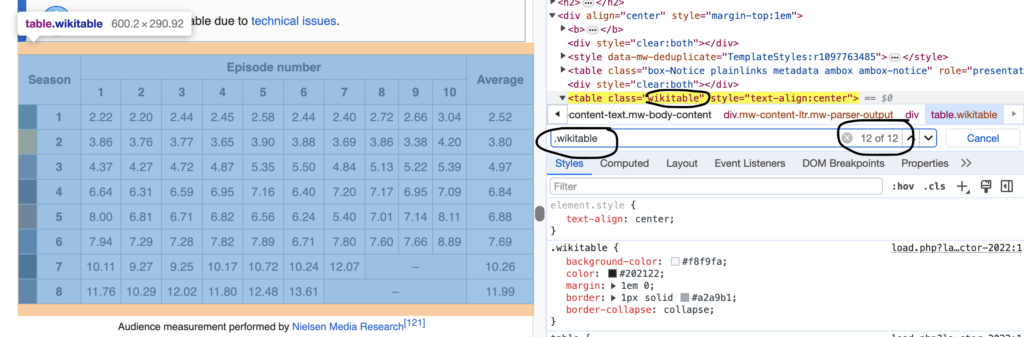
Using my preferred browser for inspection, Chrome, we can look at the tags that identify the table we are looking to scrape. Here we can see that the table we are looking for is of class type, ‘Class – wikitable’ and it is the 12th in the possible class instances. We need to note this.
Our plan is to create a script that scrapes these figures and put them into a Pandas DataFrame and save as a CSV file.
We only want limited data from this table. We only want values from the viewing cells. So we will take rows 2-9 and the data from columns 3-12. We also need to be careful of the last 2 seasons because they deviate from the normal, 10 episodes per season.
The libraries for ‘requests’, ‘BeautifulSoup’ and Pandas may already be installed on your system. If not you will need to install them. Open the terminal and enter:
> pip install requests
> pip install beautifulsoup4
> pip install pandasOpen a new ‘.py’ file and import these libraries:
# Name: GOT-Scraper.py
# Requirement: Scrapes Game of Thrones Wikipedia tables to extract the episodes and list them as dictionary entries for further use.
# Output: JSON output of the tables from wikipedia
import requests
from bs4 import BeautifulSoup as bs4
import pandas as pdNext we need to get the data from the web page and we use the requests library to do that.
# Name: GOT-Scraper.py
# Requirement: Scrapes Game of Thrones Wikipedia tables to extract the episodes and list them as dictionary entries for further use.
# Output: JSON output of the tables from wikipedia
import requests
from bs4 import BeautifulSoup as bs4
import pandas as pd
# Get the data from the website
url = 'https://en.wikipedia.org/wiki/List_of_Game_of_Thrones_episodes'
response = requests.get(url) # holds the html from the website locallyNow we need to convert this html into a BeautifuSoup object so that we can parse the tags ad data for the information we need
# Name: GOT-Scraper.py
# Requirement: Scrapes Game of Thrones Wikipedia tables to extract the episodes and list them as dictionary entries for further use.
# Output: JSON output of the tables from wikipedia
import requests
from bs4 import BeautifulSoup as bs4
import pandas as pd
# Get the data from the website
url = 'https://en.wikipedia.org/wiki/List_of_Game_of_Thrones_episodes'
response = requests.get(url) # holds the html from the website locally
soup = bs4(response.text)Beautiful Soup objects have methods that allow us to parse and drill down the hierarchy of the HTML ‘tree’ so that we can extract the information we want. Here we’ve scrapped the text of the html.
Next, we want the table with our viewing data. You will remember from earlier that we said that our data is in the 12th / last table. So we use Beautiful Soup to find ‘All’ of the tables and hold them in a list…then select / slice the lat one for us to use.
Using the ‘Inspect’ function on our browser we can find the appropriate tag for BeautifulSoup for parse. Here we can see we are looking for the class ‘wikitable’
# Name: GOT-Scraper.py
# Requirement: Scrapes Game of Thrones Wikipedia tables to extract the episodes and list them as dictionary entries for further use.
# Output: JSON output of the tables from wikipedia
import requests
from bs4 import BeautifulSoup as bs4
import pandas as pd
# Get the data from the website
url = 'https://en.wikipedia.org/wiki/List_of_Game_of_Thrones_episodes'
response = requests.get(url) # holds the html from the website locally
# lets make the soup
soup = bs4(response.text)
# get all the tables from the soup in a list - remember from inspecting we want objects of class 'wikitable'
tables = soup.find_all('table', {'class': 'wikitable'})
# and we only want the last table
table = tables[-1]Next we want the data. But we only want the numbers. So the top 2 rows from the table in the screen shot are not relevant.
We’ll put our rows in a python list so we can work with then later. In HTML table rows use the tags <tr> so we can make a list of those with their enclosed data.
# Name: GOT-Scraper.py
# Requirement: Scrapes Game of Thrones Wikipedia tables to extract the episodes and list them as dictionary entries for further use.
# Output: JSON output of the tables from wikipedia
import requests
from bs4 import BeautifulSoup as bs4
import pandas as pd
# Get the data from the website
url = 'https://en.wikipedia.org/wiki/List_of_Game_of_Thrones_episodes'
response = requests.get(url) # holds the html from the website locally
# lets make the soup
soup = bs4(response.text)
# get all the tables from the soup in a list - remember from inspecting we want objects of class 'wikitable'
tables = soup.find_all('table', {'class': 'wikitable'})
# and we only want the last table
table = tables[-1]
# get a list of the rows
rows_list = [] # empty list
rows = table.find_all('tr') # we use soup to 'find_all' of the rows
# then step through the rows (excluding the top 2 by slicing ([2:]) adding them to our new list
for row in rows[2:]:
rows_list.append(row)This next series of steps takes a little careful consideration. We need to:
- Step through each row.
- Collect all of the HTML for each cell from that row – those tagged ‘td’.
- For each cell, we use Beautiful Soup to extract the number text.
- We check to make sure the value is not a ‘-‘ as we have in the last 2 series and we convert it to a float number and store it in our interim list.
- Step through these lists and check to see if there are 10 elements. If not, add 0.0 to the end until there are at least 10 elements.
- For those lists with greater than 10 elements (including the average viewer) limit to 10.
- Add them to the final list. This list should now hold 8 lists of 10 elements. The data we want.
# Name: GOT-Scraper.py
# Requirement: Scrapes Game of Thrones Wikipedia tables to extract the episodes and list them as dictionary entries for further use.
# Output: JSON output of the tables from wikipedia
import requests
from bs4 import BeautifulSoup as bs4
import pandas as pd
# Get the data from the website
url = 'https://en.wikipedia.org/wiki/List_of_Game_of_Thrones_episodes'
response = requests.get(url) # holds the html from the website locally
# lets make the soup
soup = bs4(response.text)
# get all the tables from the soup in a list - remember from inspecting we want objects of class 'wikitable'
tables = soup.find_all('table', {'class': 'wikitable'})
# and we only want the last table
table = tables[-1]
# get a list of the rows
rows_list = [] # empty list
rows = table.find_all('tr') # we use soup to 'find_all' of the rows
# then step through the rows (excluding the top 2 by slicing ([2:]) adding them to our new list
for row in rows[2:]:
rows_list.append(row)
final_lists=[]
row_values =[]
row_list =[]
for row in rows_list:
row_list =[]
# Note that this takes the first cell in each row rather than reading across the row
cells = row.find_all('td')
for cell in cells:
value = cell.text
if value != '–': # if the cell contains a '-' don't process it
row_list.append(float(value)) # make the text a float number and add it to the list
# Make sure there are 10 elements in the list to make the dataframe 10x8 elements
while len(row_list)<10:
row_list.append(0.0)
# only capture the data, not the average
if len(row_list)>10:
row_list = row_list[:10]
final_lists.append(row_list) #add it to the final list of data Finally, we want to load the data into a Pandas DataFrame and save the data as a ‘csv’ file without any index.
# Name: GOT-Scraper.py
# Requirement: Scrapes Game of Thrones Wikipedia tables to extract the episodes and list them as dictionary entries for further use.
# Output: JSON output of the tables from wikipedia
import requests
from bs4 import BeautifulSoup as bs4
import pandas as pd
# Get the data from the website
url = 'https://en.wikipedia.org/wiki/List_of_Game_of_Thrones_episodes'
response = requests.get(url) # holds the html from the website locally
# lets make the soup
soup = bs4(response.text)
# get all the tables from the soup in a list - remember from inspecting we want objects of class 'wikitable'
tables = soup.find_all('table', {'class': 'wikitable'})
# and we only want the last table
table = tables[-1]
# get a list of the rows
rows_list = [] # empty list
rows = table.find_all('tr') # we use soup to 'find_all' of the rows
# then step through the rows (excluding the top 2 by slicing ([2:]) adding them to our new list
for row in rows[2:]:
rows_list.append(row)
final_lists=[]
row_values =[]
row_list =[]
for row in rows_list:
row_list =[]
# Note that this takes the first cell in each row rather than reading across the row
cells = row.find_all('td')
for cell in cells:
value = cell.text
if value != '–': # if the cell contains a '-' don't process it
row_list.append(float(value)) # make the text a float number and add it to the list
# Make sure there are 10 elements in the list to make the dataframe 10x8 elements
while len(row_list)<10:
row_list.append(0.0)
# only capture the data, not the average
if len(row_list)>10:
row_list = row_list[:10]
final_lists.append(row_list) #add it to the final list of data
# Convert to a Pandas DataFrame and use the Pandas 'to_csv' method to save as a CSV file
viewers = pd.DataFrame(final_lists)
viewers.to_csv("viewer.csv", index = False)We should now have a viewer.csv file with our data stored, ready for analysis.
Here is the DataFrame:
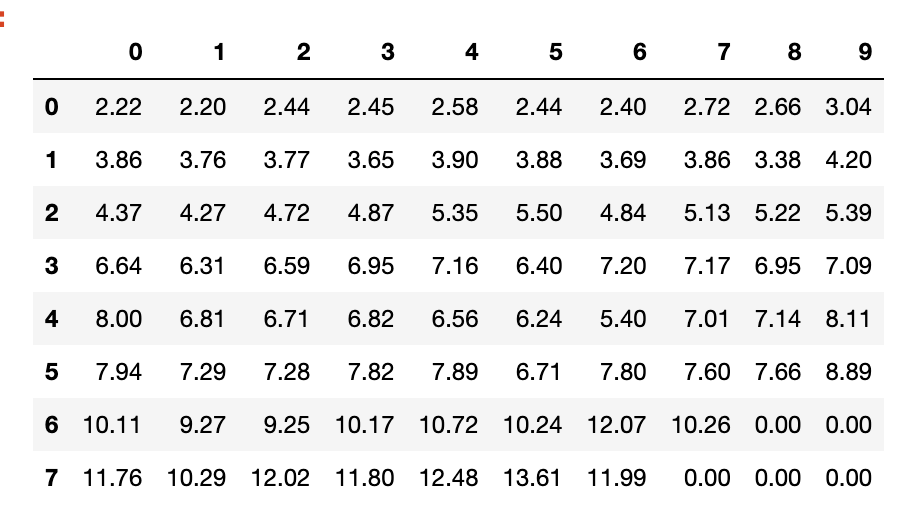
Here is the viewers.csv file:

Here is the full code:
# Name: GOT-Scraper.py
# Requirement: Scrapes Game of Thrones Wikipedia tables to extract the episodes and list them as dictionary entries for further use.
# Output: JSON output of the tables from wikipedia
import requests
from bs4 import BeautifulSoup as bs4
import pandas as pd
# Get the data from the website
url = 'https://en.wikipedia.org/wiki/List_of_Game_of_Thrones_episodes'
response = requests.get(url) # holds the html from the website locally
# lets make the soup
soup = bs4(response.text)
# get all the tables from the soup in a list - remember from inspecting we want objects of class 'wikitable'
tables = soup.find_all('table', {'class': 'wikitable'})
# and we only want the last table
table = tables[-1]
# get a list of the rows
rows_list = [] # empty list
rows = table.find_all('tr') # we use soup to 'find_all' of the rows
# then step through the rows (excluding the top 2 by slicing ([2:]) adding them to our new list
for row in rows[2:]:
rows_list.append(row)
final_lists=[]
row_values =[]
row_list =[]
for row in rows_list:
row_list =[]
# Note that this takes the first cell in each row rather than reading across the row
cells = row.find_all('td')
for cell in cells:
value = cell.text
if value != '–': # if the cell contains a '-' don't process it
row_list.append(float(value)) # make the text a float number and add it to the list
# Make sure there are 10 elements in the list to make the dataframe 10x8 elements
while len(row_list)<10:
row_list.append(0.0)
# only capture the data, not the average
if len(row_list)>10:
row_list = row_list[:10]
final_lists.append(row_list) #add it to the final list of data
# Convert to a Pandas DataFrame and use the Pandas 'to_csv' method to save as a CSV file
viewers = pd.DataFrame(final_lists)
viewers.to_csv("viewer.csv", index = False)